
Overview
Data INRAE is a French institutional data repository (INRAE ; France's National Research Institute for Agriculture, Food and Environment), part of “Recherche Data Gouv” (French Data Repository), and based on Dataverse technology. Datasets are referenced with key words, selected by dataverse managers. In the current way, these managers can use any terms or semantic artefacts and few belong to control vocabularies. This use case aims to connect AgroPortal with Data INRAE. AgroPortal is a semantic artefacts catalog for agri-food and related domains. The goal of the connection is to facilitate the control vocabularies use for keyword completion. Control vocabularies improve our ability to find and reuse stored data and participate in their interoperability. In fine, a better keyword usage should improve data INRAE FAIRness. In this use case, we will evaluate the practices and data FAIRness evolution.
In recent years, an increasing number of data repositories have been deployed to address the need of research data publication and reuse. In the case of INRAE, France's National Research Institute for Agriculture, Food and Environment, research data is either shared via domain repositories or via an institutional repository: Data INRAE, now a part of the French federated national research data platform Recherche Data Gouv.
This national repository is based on the open source research data repository software Dataverse. Data repositories softwares such as Dataverse allow datasets to be documented by metadata, but these metadata fields often function as sole texts rather than semantic concepts, without enrichment, expanded search on related terms or multilingualism.
Semantic artefacts of interest to INRAE are hosted in AgroPortal, a repository for ontologies and other semantic artefacts in agri-food and related domains. AgroPortal is based on the generic technology OntoPortal developed jointly by INRAE-MISTEA, University of Montpellier and the OntoPortal Alliance. AgroPortal allows users to search and browse for terms in a user-friendly interface and can also be called automatically by tools through APIs.
This use case aims at bridging the gap between these platforms; data repositories and semantic artefacts catalog, by developing a connector in Data INRAE to be able to use semantic artefacts from AgroPortal in an user-friendly way, and make it usable and available to all users of Dataverse or Ontoportal technologies.
Implementation solution: Connector between Data INRAE and AgroPortal
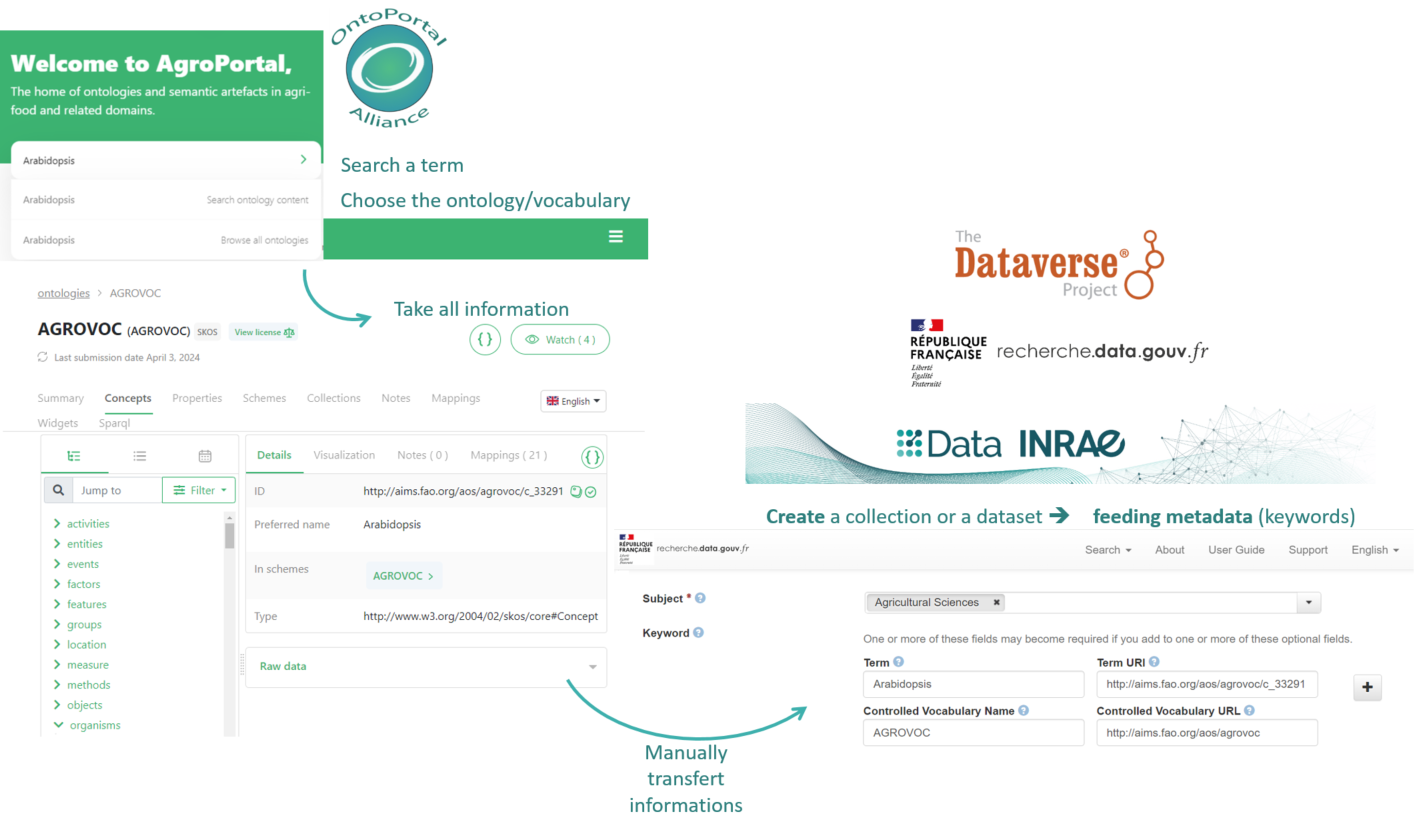
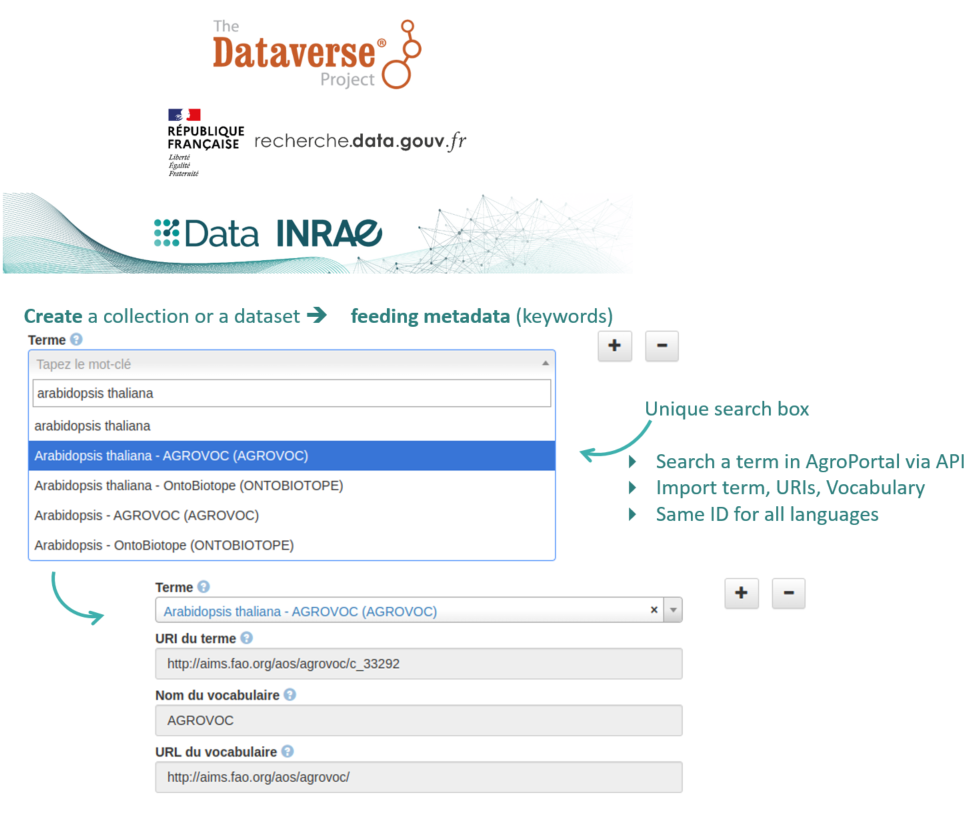
Concretely, with this new feature (cf. Fig2),
- The dataverse manager selects relevant semantic artefacts from AgroPortal
- The data depositor picks keywords from ontologies and thesauri that have been connected
- Dataverse records URIs and any relevant information for these keywords
- Information from the selected keywords can be exported with other metadata of a dataset
Challenges that need to be addressed
This integration should make it possible to propose relevant semantic artefacts to the community with terms from agri-food vocabularies being available on AgroPortal (and potentially in several others semantic artefact catalogs).
#user-friendliness - the evolutions proposed must ease the work of describing and searching datasets while remaining intuitive and fast-responding. The users will be involved in the specifications and tests of the new features.
#multilinguism - users of Data INRAE generally work in English or French and AgroPortal semantic artefacts can be multilingual. Evolutions of the Agroportal API are considered in link with T4.2.
#modularity - In the case of pluridisciplinary data repositories like the Recherche Data Gouv repository, depositors from various communities may need to select concepts from specific vocabularies. To address this need, the set of vocabularies to be used must be configurable at dataverse collections level.
#sustainability - At this time, a key challenge in this use case is to connect Data INRAE and AgroPortal, while making this connection generic and reusable for other installations of OntoPortal and Dataverse. For instance, we have to change the export feature to include the URIs of controlled terms used to index. The evolutions brought by the use case are discussed and shared with both developers’ communities.
#evaluation - the use case must allow evaluating the impact of the evolutions proposed on the data FAIRness, Findability in particular.
Expected impact of the Use Case
The use case outputs will improve the FAIRness of Data INRAE’s datasets (research and technical agri-food data). The connection with the vocabularies repository (AgroPortal) will result in more and richer keywords added by data producers. In addition, the use of semantic artefacts will enable the multilingual and synonymy search for increased findability and accessibility of datasets.
The use of documented, identified, unambiguous and more domain-relevant keywords thanks to external and specific semantic artefacts systems, which will allow increasing interoperability of the datasets. This will also promote and ease the use of standard terms and semantic artefacts for the communities.
These benefits will be achieved, while providing a faster and easier metadata completion, thanks to the simplification of metadata fields and their filling.
In addition, this should result in an increased use of the semantic artefacts in platforms using this connector. For example, AgroPortal will benefit from Agricultural Science users' needs for additional or improved terms from Data INRAE. Other scientific domains willing to be able to benefit from such features should also result in new terms and artefacts in semantic artefacts catalogs.
As these developments will be compatible not only with Data INRAE and Agroportal installations but for the softwares they use (respectively Dataverse and Ontoportal). The feature and its benefits will be reusable on all installations of these softwares in various domains.
Expected outputs
The tangible outcomes of this use case are:
- Dataverse-OntoPortal connector publically available in the community’s repository
- Global improvement of semantic artefacts use in Dataverse
- Analysis of current practices and impact of the evolution on users and on datasets findability
- Guidelines on criteria to select relevant semantic artefacts for a data repository