D6.2: Core metadata schema for legal interoperability
The aims and structure of the deliverable
FAIR-IMPACT aims to support the implementation phase of the European Open Science Cloud (EOSC). To this end, FAIR-IMPACT has a focus on the EOSC Interoperability Framework. The perspective for this deliverable is on legal interoperability for core metadata schemes for research datasets which refers to the ability to share, access, and use research data across different legal jurisdictions and institutions while complying with relevant laws, regulations, and policies.
At first, the deliverable illustrates the impact of the GDPR on legal interoperability in practice. The deliverable then presents as a landscape analysis the foundation for a legal interoperability framework, by evaluating the relevance of existing widely adopted metadata schemas and controlled vocabularies used in data repositories for the description of legal constraints. Their use and implementation are illustrated with specific use cases, which also validate the findings by highlighting the challenges faced and addressed by different communities.
As a core metadata schema to foster legal interoperability between research datasets the Dataset Catalogue (DCAT)-standard stands out as the best-suited tool to describe datasets, facilitates interoperability between data catalogues, portals, and repositories, and allows for the enrichment of metadata in the analysis. Additional controlled vocabularies support aspects of legal interoperability: international licences (AT-licence), access control policies (ODRL), copyright and intellectual property (DCMI, PROV-O), data protection and privacy (DPV).
Few mappings between metadata schemas are available, they could be improved with new ones in addition to the ones considered here. The FAIRCore4EOSC has deployed the Metadata Schema and Crosswalk Registry (MSCR), which, thanks to its ease of access, could enhance the uptake of such mappings effectively.
The recommendation of the DCAT standard as building block for legal interoperability supported by additional controlled vocabularies could also be explored by the new, to-come EOSC Interoperability Task Force, and support programs could be put together to stimulate the adoption of good practices in the domain.
Schemas and vocabularies under consideration
The initial phase toward the recommendation of a framework for legal interoperability is the evaluation of relevant metadata schemas or controlled vocabularies for this purpose with the objective to identify the most appropriate ones. A list of widely-used schemas and vocabularies has been identified, and a set of criteria has been put together to evaluate them.
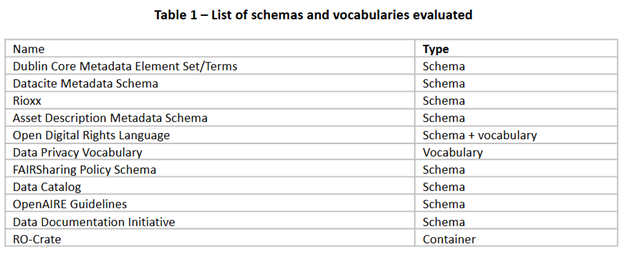
Evaluation criteria
The EOSC Interoperability Framework recommends that a minimum metadata model should be proposed to ease discovery over existing federated research data and metadata to facilitate findability and to support interoperability not only within domain-specific services or repositories, but also across domains and communities.
EOSC IF recommends a minimum metadata set to describe metadata records for FAIR digital
objects where it is possible to use various existing metadata schemes and aggregators’ guidelines. This applies for any rights and terms of access information for this digital object. Typically, rights information includes a statement about various property rights associated with the digital object, including intellectual property rights. The EOSC IF recommends to refer to a rights statement with a URI, or a literal value (name, label, or short text) if the former is not possible or feasible.
These metadata elements are essential for the reusability of the digital object and consist of:
- Standardised version of the licence name, URI of the licence;
- Copyrights holder (use authority control databases for persons or institutions if available and persistent identifiers - e.g., ORCID, ISNI, VIAFID - or national authority database of personal and corporate names);
- Access rights;
- Confidentiality declaration;
- Special permissions, restrictions, conditions, disclaimers;
- Citation requirements;
- Level of access, access type, authentication, authorisation, access method, and granularity.
The schemas and vocabularies in the next sections will be evaluated against these recommendations, i.e. their ability to convey this information for scientific datasets.
In order to ease the process, these elements have been gathered in three categories:
- Access policies (access rights, level of access, access type, access method, etc.);
- Copyright and intellectual property (copyrights holder, licence, citation requirements, etc.);
- Data protection and privacy (confidentiality declaration, special permissions, etc.).
In addition, other non-technical criteria will be considered during the evaluation, such as:
- The level of adoption and the existence of a community of practice,
- The provision of support,
- The availability of tools.
Core metadata schema for legal interoperability
From the metadata standards designed specifically for describing datasets in a machine-readable format which have been evaluated, DCAT seems to be the tool of choice as it provides a standardised way to describe datasets, facilitates interoperability between data catalogues, portals, and repositories, and allows for the enrichment of metadata by providing a rich, expandable set of properties to describe various aspects of datasets. Its uptake by different communities is large, and a number of application profiles exist to reflect specific usage and implementation. It integrates widely-used other generic standards (DublinCore) and has already been mapped to others (e.g., Datacite, ADMS, schema.org, etc.). DCAT editors and validators are available online, which makes it handier to integrate.
In order to enable the comparison and machine-actionability of the legal constraints bound to datasets, controlled vocabularies are the most effective and flexible tool at our disposal and they should complement the DCAT metadata schema efficiently. Different sub-topics have been identified, for which solutions exist, namely: licences, access policies, intellectual property rights, data privacy.
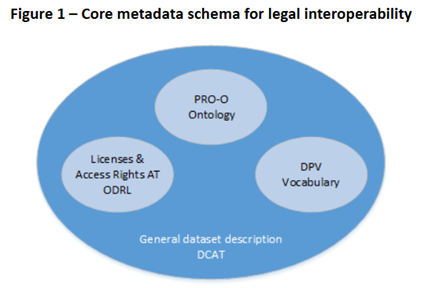
Access Policies
The Access Rights authority table is a controlled vocabulary listing the access rights or restrictions to resources. It i designed for but not limited to DCAT simple descriptions of access rules for datasets (e.g., public, sensitive, confidential). These two authority tables are maintained by the Publications Office of the European Union on the EU Vocabularies website. For more elaborated constraints, ODRL enables the definition of access control policies that express permissions and/or prohibitions associated with data. Some recommendations and examples about the integration of ODRL in DCAT are available.
Copyright and Intellectual Property
The Licence authority table is a controlled vocabulary which exhaustively lists the different licences available internationally which can be tagged on publications, datasets, databases or software. DCMI terms include a RigthsHolder property that can suffice for simple cases, but PROV-O allows more complex descriptions, e.g. the organisation to which the rights holder belongs, or the context of the generation of the dataset. It has been mapped to DCMI, and can be integrated to DCAT by creating a DCAT catalogue as a subclass of a PROV-O entity.
Data Protection and Privacy
Data Privacy Vocabulary (DPV) can be utilised as a controlled vocabulary for invoking privacy and data protection-specific terms which can be used in ODRL.