
The AnaEE (Analysis and Experimentation on Ecosystems) Research Infrastructure offers experimental facilities for studying ecosystems and biodiversity. A pipeline featuring several applications is developed, based on interoperability of its components and the use of shared semantic artifacts, mainly AnaeeThes thesaurus and OBOE-based AnaeeOnto ontology (to be published). The goal of this pipeline is to generate interoperable datasets and the associated metadata records. The AnaEE semantic workflow consists of 3 steps:
- At step 1 the observed /measured variable and the acquisition contexts are modeled as a generic graph based on the ontology.
- At step 2 a dedicated pipeline allows the automation of the annotation process and the production of graph-hosted semantized data.
- At step 3, a second pipeline is devoted to the exploitation of these semantized data through the generation of standardized metadata records (presently GeoDCAT and ISO) and, data files (presently in NetCDF and csv format) from selected perimeters (acquisition sites, measured variables, experimental factors, years...) (https://hal.inrae.fr/hal-03234155 and figure 1).
The semantized data and metadata produced are intended to feed discovery and access portals, data repositories and (Virtual Research Environment) VRE-type platforms.
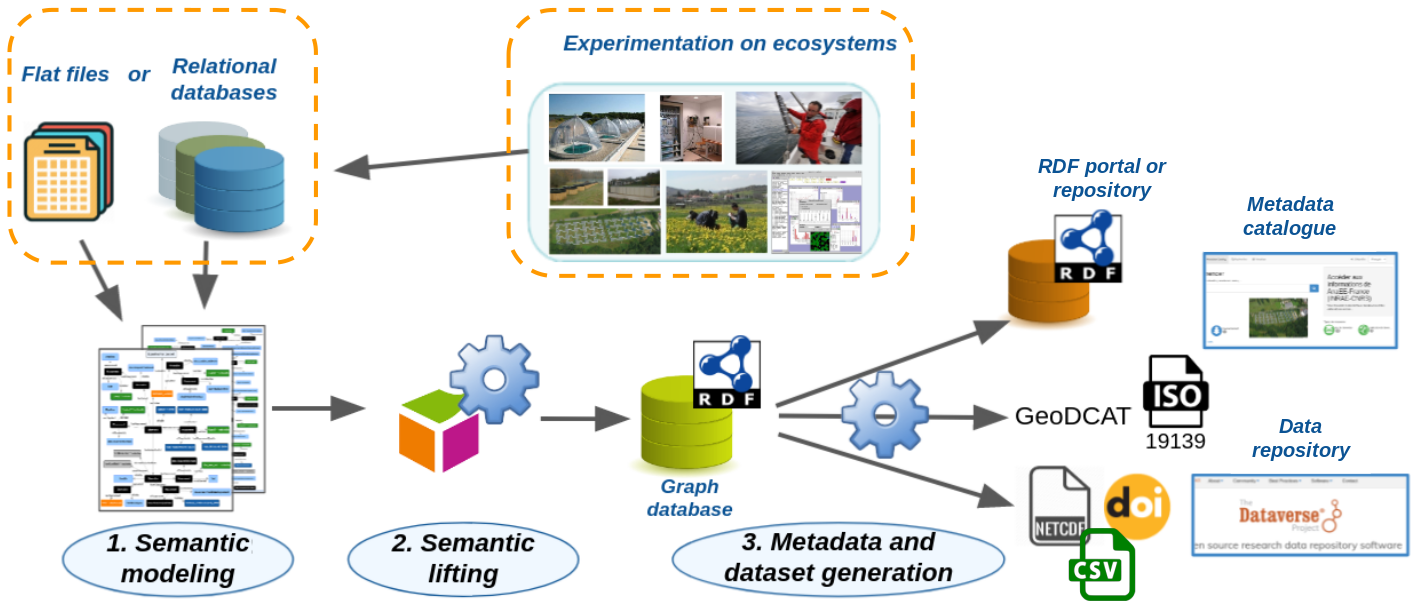
As shown above, the generated datasets and metadata are pushed to the Recherche Data Gouv platform (based on Dataverse). For that reason, AnaEE metadata enriched with controlled keywords must remain fully compatible with the Dataverse metadata standard.
Semantic artefacts (SA) in use within the AnaEE semantic tools and data repositories
In the context of FAIR IMPACT, we focus on the use of SA at the 3rd step of the workflow, i.e for metadata generation. However, it should be noted that SA are already involved in the modeling phase (step 1). Referred to as SemData, the application aims to enrich the description of the dataset by the addition of ‘keywords’ supplied by controlled SA in order to complete the description of the data asset provided by the modeling step. Three types of enrichment processes are proposed to the data providers :
1. Keyword automatic checking & enrichment
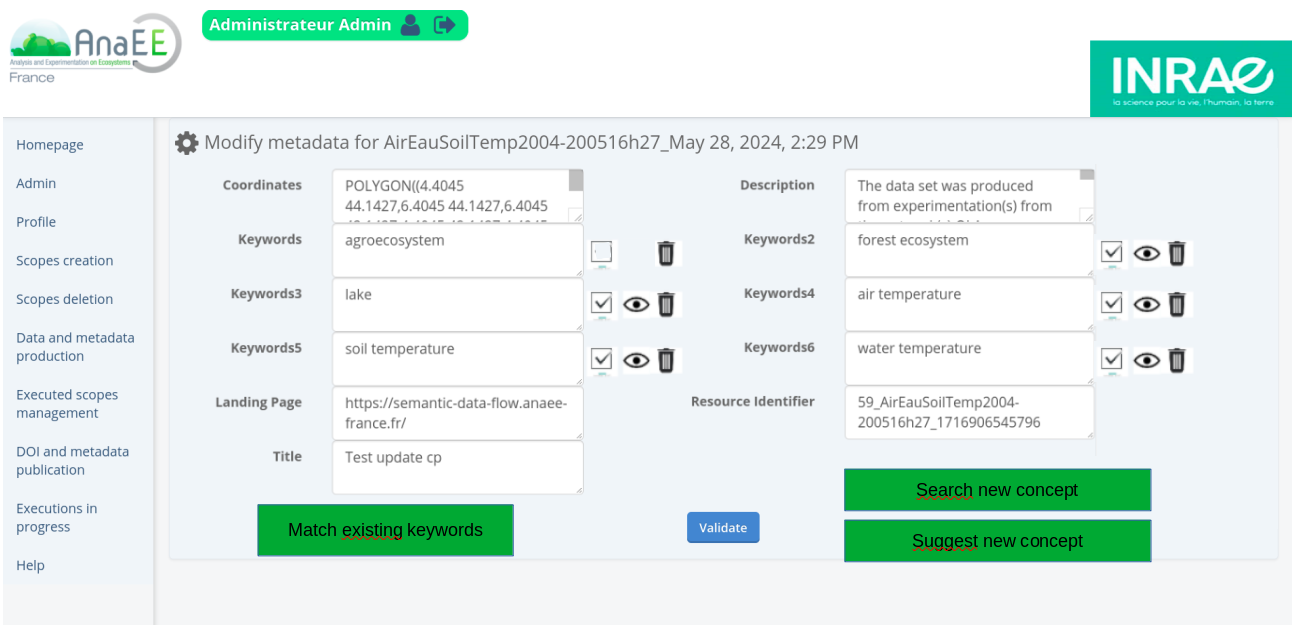
In this situation, some keywords resulting from the pipeline are simple strings, without semantic reference. The application uses the Agroportal search API to search for the matching concept(s) in the AnaEE Thesaurus. Then, as shown in figure 2, the user is able to access keyword full description, and for keywords that do not match (unchecked box), decide to get rid of them (trash icon). Meaningful icons next to each keyword text box allows access to the full keyword description as provided by Agroportal (definition, synonyms, URI…) and possibly delete the keyword.
2. Keyword manual selection
In this second situation, the data producer wants to enrich the metadata record with additional keywords. The interface of the AnaEE dataset and metadata generation tool must allow to pick up concepts from thematic vocabularies, especially from AnaeeThes, to fill in the “keywords” metadata elements.
The user starts writing a keyword and the agroportal API call proposes several candidate keywords. One or more of the proposed keywords is/are then selected. These keywords can be added to the metadata records or ignored (Figure 3).

Here, the user entered “air temperature” and the search function of Agroportal returns some matching keywords. The UI displays them and allows the user to add one or more keywords to the metadata records.

AnaeeThes is used as the default SA, but the UI allows the use of other controlled vocabularies.
3. Keywords suggestion from textual description
Here, the objective is to offer the possibility to enrich the metadata records with keywords by matching a SA on a narrative description of dataset content. This description is automatically generated by SemData from information collected by the pipeline. As an abstract-like description of the dataset, it provides information about sites, variables and time periods selected by the user as criteria generating the dataset (i.e : ‘The data set was produced from observations collected on the site(s) {sites} in the ecosystem(s) {ecosystems}. Measurements are about the following variables: {variables}... ‘.
The user can press the “suggest new concept” button (see Figure 2). The abstract has to be pasted in a combo box. The user may also complete (or replace) this default text with some other meaningful narrative. Then the user launches an “annotator“ call to the Agroportal API on the description text, which returns candidate concepts.

For sub use cases 2 & 3, the “Concept Selector” is designed to facilitate the choice for the user. We focus on displaying fully qualified information. The preferred term and concept definition are needed. The user can also open a new web browser tab to consult the concept landing page.
In the application, each keyword is stored with its preferred term, its URI, the name and URI of the SA it comes from…, elements that cover the information expected by Dataverse instances like Recherche Data Gouv, for qualifying keywords.
Challenges that need to be addressed
In order to implement all the functionalities described within the AnaEE use case, we inserted Agroportal API calls in the AnaEE application. We also changed our data model inside the application, to store all keyword related information. We also adapted API calls to the dataverse repository, to include keywords defined by several parameters: concept, URI, SA URL, SA name.
Expected impact of the Use Case
After the integration of the API calls to Agroportal, the keywords associated by default in each dataset are fully described and above all compatible with the description of the keywords in the dataverse repository of recherche.data.gouv. The user also benefits from a mechanism for suggesting new keywords, based on the description of the dataset. For datasets already published, there will be no impact of this development, unless they are regenerated through the adhoc functionality offered by the AnaEE pipeline.
Expected outputs
Production of semantically enriched, vocabulary based, description of the datasets. Keywords need to be fully compatible with the dataverse keyword data model. As a consequence, our thesaurus updating process needs to be more accurate with the changes involved by adding new variables, when new information systems benefit from the semantic annotation and data publication services offered by the pipeline.