
Short Use Case overview
DANS (Data Archiving and Networked Services) improved the FAIRness (Findable, Accessible, Interoperable, and Reusable) of its repository service by transitioning from a generic repository system, EASY, to four discipline-specific repositories called "Data Stations." Each Data Station is curated with relevant communities, enables the addition of custom metadata fields and discipline specific controlled vocabularies, improving metadata quality and interoperability. Data is mapped to and can be exported in multiple formats like DublinCore, DataCite, and Schema.org. The new Data Stations use Dataverse software, as opposed to EASY, which was based on the FEDORA system and became outdated.
Use case description
Use case: DANS Data Stations
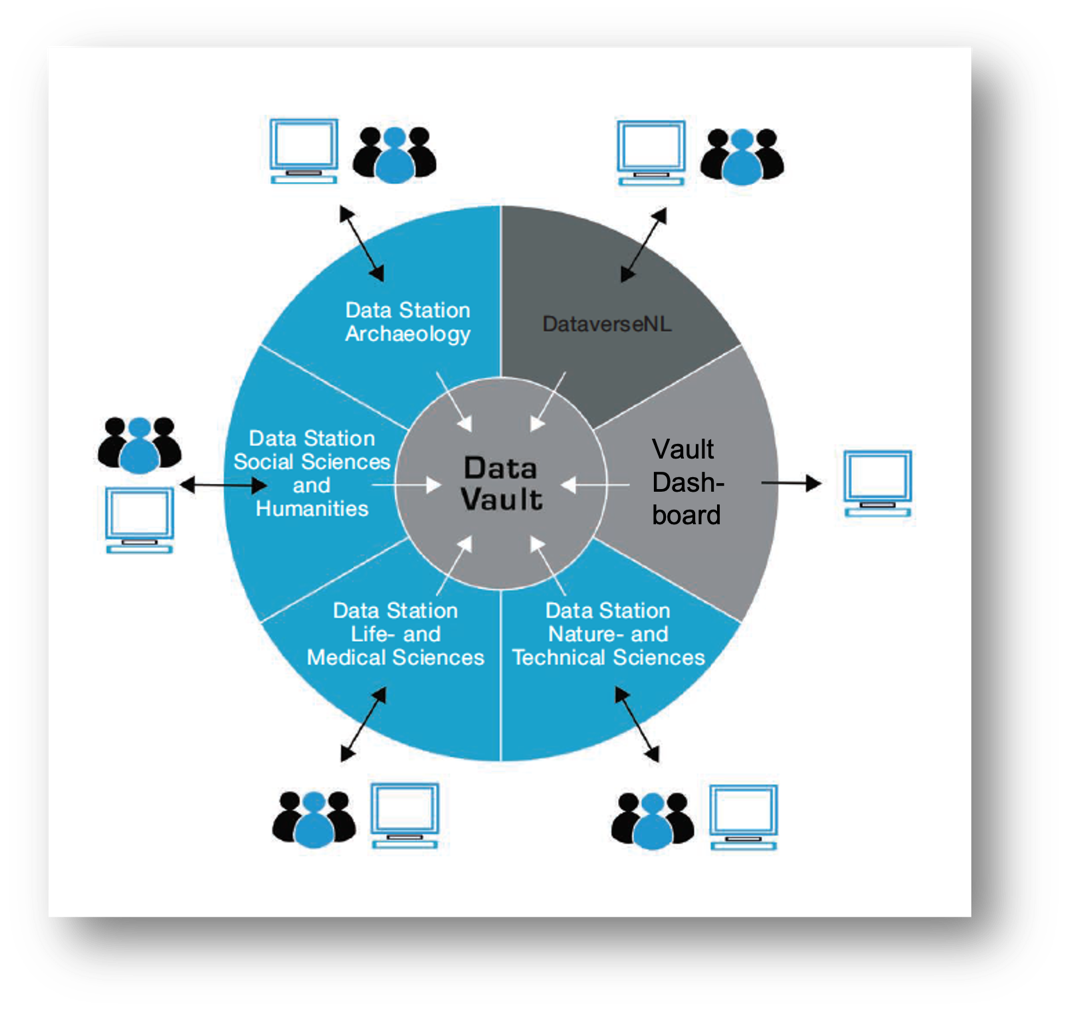
DANS (Data Archiving and Networked Services) is the Dutch national expertise centre and repository for research data. Its main objective is to facilitate and improve the long-term storing and sharing of research datasets, thus aiding its mission of enhancing the reusability of research data and the quality of scientific research. DANS is running various Dataverse instances for different disciplines paired with a long-term preservation repository, and calls them Data Stations. DANS’ repository services currently include four discipline-specific data stations; a research data repository service for institutions, DataverseNL; and a preservation repository, the Data Vault. DANS also offers expertise and training on topics like Research Data Management, FAIR data, and Open Science through its Research Data Management Expert and Training teams.
Context and objectives
To improve the FAIRness of its repository service, DANS moved from one generic repository, Electronic Archiving SYstem or simply EASY, to four discipline-specific ‘Data Stations’: Archaeology (https://archaeology.datastations.nl, launched in 2022), Social Sciences and Humanities (https://ssh.datastations.nl, SSH, launched in the spring of 2023), Life Sciences (https://lifesciences.datastations.nl, soft launch in December 2023), and Physical and Technical Sciences (https://phys-techsciences.datastations.nl, soft launch in December 2023). For each of the Data Stations there are also special links to the communities. For instance the Physical and Technical Sciences Data Station is curated together with the Technical University of Delft. The Archeological Data Station serves as a reference archive for all archeological reports. This role is commissioned by the RCE (“Rijksdienst voor Cultureel Erfgoed”, the Dutch Cultural Heritage Agency).
The implementation of discipline-specific archives has facilitated the addition of discipline-specific metadata with their own specific controlled vocabularies, in addition to the already present rich generic metadata. Metadata has been mapped to, and can be exported as, DublinCore, DataCite, Schema.org, OpenAIRE, DDI, and more. EASY was developed by DANS team internally based on the FEDORA system, however the Data Stations rely on the Dataverse software (https://dataverse.org/).
For several generic metadata fields and for many of the discipline-specific metadata fields, the depositor chooses values from a dropdown menu or automatic completion field. The lists, or semantic artefacts, underlying these values are mostly hard-encoded in the DANS Dataverse instance(s), and using Dublin Core and DataCite 3.0 and 4.0 properties (Table 1). For language and spatial coverage ISO standard lists are used, ISO 639-2:1998 and ISO 3166-1:2013, respectively. Also for the (more recently added) discipline-specific metadata blocks, the values are derived from internationally used vocabularies, greatly improving interoperability. For the Data Station SSH this concerns terms from the CESSDA ELSST Thesaurus and the CESSDA Topic Classification; addition of DDI terms is planned for the near future. For the Data Station Archaeology this concerns terms from the ‘Archeologisch Basis Register’ (ABR) of the Netherlands (https://data.cultureelerfgoed.nl/term/id/abr.html).
The process of adding domain-specific metadata and vocabularies is still ongoing for the Data Station Life Sciences and the Data Station Physical and Technical Sciences in collaboration with relevant partner organisations to assess community needs.
Table 1
| Data Station | Metadata element label | Source | Source URL |
| All | Indentifier Type | List created by DANS based on identifiers known to be used by the DANS community | n/a |
| All | Subject | DANS, based on Dataverse list | n/a |
| All | Language | ISO 639-2:1998 | |
| All | Spatial Coverage | ISO 3166-1:2013 | |
| All | Contributor Type | A mix of terms from DataCite ContributorType version 3.0 and 4.0 | https://schema.datacite.org/meta/kernel-3.0/; https://schema.datacite.org/meta/kernel-4.0/ |
| All | Audience | NARCIS | https://vocabs.datastations.nl/NARCIS/en |
| All | Collection | DANS collections | https://vocabs.datastations.nl/DansCollections/en/ |
| All | Relation, Related Material Type | Elements from DataCite and DublinCore. A mix of elements from Dublin Core properties and DataCite 3.0 and 4.0 | https://www.dublincore.org/specifications/dublin-core/dces/; https://schema.datacite.org/meta/kernel-3.0/; https://schema.datacite.org/meta/kernel-4.0/ |
| All | Personal Data in Dataset | List created by DANS | n/a |
| SSH | Keyword ELSST | ELSST | https://thesauri.cessda.eu/elsst-4/en/ |
| SSH |
Topic Classification CESSDA |
CESSDA Vocabulary Service | https://vocabularies.cessda.eu/vocabulary/TopicClassification |
| SSH | [Nothing yet, planned use] | DDI Analysis Unit, Mode of Collection; Sampling Procedure; Time Method; Type of Instrument | https://ddialliance.org/controlled-vocabularies (links to CESSDA Vocabulary Service) |
| ARCH | Archaelogy report | ABR+ | https://vocabs.datastations.nl/ABR/en/ |
| ARCH | Relation metadata | NARCIS | https://vocabs.datastations.nl/NARCIS/en |
| ARCH | Methods of recovery | ABR+ | https://vocabs.datastations.nl/ABR/en/ |
The third-party vocabularies are available through a semantic artefact catalogue relying on the SKOSMOS, web-based tool providing services for accessing controlled vocabularies: https://vocabs.datastations.nl/en/. The vocabularies to be used in the DANS Data Stations are fed into here. The Data Station is then connected to the SKOSMOS instance to fill out the dropdown lists of the metadata elements, providing an easy way for users to select values from the third-party vocabularies. Custom settings required to connect vocabularies available in SKOSMOS with a plugin implemented as an external Javascript application, available through https://github.com/gdcc/dataverse-external-vocab-support.
Technologically, by using the Dataverse archival software, DANS became an active participant in the Open Source community around Dataverse. Led by Harvard University, regular updates of the so-called ‘master/main’ branch are developed with new features. For example, a Controlled Vocabularies plugin was developed by the DANS team in the SSHOC project and was incorporated to Dataverse by Harvard and GDCC, and since then has become part of the out-of-the-box distribution for the community. The institutions hosting Dataverse instances are free to implement new versions into their local systems, depending on their own requirements. However, being part of the Dataverse community also enables DANS to explore new innovative solutions in projects, based on experiences gathered from the day-to-day use and curation of Data Stations. When it comes to challenges and implemented solutions we will indicate which of them has been already implemented in the production system, which of them have been taken up in the Dataverse main releases (but not yet implemented in the DANS instance), and which of them are explorations even new for the Dataverse main release discussion. Within T4.2 we are working with other use cases (e.g., the OntoPortal/Dataverse connector) to reach out the same maturity by learning from our experience and making the connector part of the default Dataverse distribution.
Challenges and solutions implemented
Challenges (identified, not all to be addressed):
Data Station Archaeology terms such as keywords are available in Dutch taxonomy only and filled during depositing in the DANS Data Station. Available for searching in English in the ARIADNE portal.
- Objective: Look into augmenting the vocabularies with an English translation. ODISSEI semantic enrichment workflow can be used to get multilingual translations available in Data Stations.
Not all depositors use the available metadata fields.
- Solutions to link external controlled vocabularies to the DANS Data Stations have been implemented in the DANS production system and in Dataverse main releases, but their uptake by depositors remains a little limited.
- Objective: Increase the use especially of rich metadata, especially also those fields that use international vocabularies.
- Solution: Write a clear guide on why and how to use the metadata fields and their controlled vocabularies.
Currently the keywords are free-text.
- Objective: Connect them to internationally recognised controlled vocabularies / thesauri.
- Solution: The technical solution already exists.
Using a SKOSMOS instance has clearly been a useful solution of connecting published vocabularies to Dataverse instances. However, while it has been documented on GitHub, reusability of the solution would be greatly improved by additional documentation.
- Solution: document the whole approach to make it reusable.
Vocabulary sustainability: how are updates to the original vocabularies dealt with? For example, ELSST Thesaurus in the DANS SKOSMOS instance has version 3 but CESSDA already updated it with version 4.
- Objective: track changes and synchronise the same vocabularies hosted by different parties
- Solution: requires development of some workflow to archive new versions of controlled vocabularies before publishing in SKOSMOS or OntoPortal, and keep provenance.
Vocabularies available in OntoPortal instances, currently especially relevant for the Data Stations Life Sciences and Physical and Technical Sciences. How can these be directly connected to Dataverse instances like the DANS Data Stations?
- Objective & solution: develop a connection between OntoPortal and Dataverse in partnering with the INRAE’s use case (RDG/OntoPortal) in the same task (T4.5)
- This solution is new even for the Dataverse main release discussion.
Proposed solutions to work on as part of FAIR-IMPACT T4.5:
- Documenting the approach
- How to transform the free text terms by reference to controlled vocabulary terms?
- How to connect several controlled vocabularies to a single data repo/metadata element? (Could there be a way to have AAT AND ABR?)
- Documenting the use of vocabularies in the Data Stations. How can we take user requirements about vocabularies integration into account?
- How are the semantic terms used in the repository index, how are they exported in the various export flavours or served by APIs?
- How are the terms used by systems that harvest the data stations and mapping technique?
- How is the harvesting done from the DS Archaeology by ARIADNE (for example) where mapping of ABR to AAT should be implemented by ARIADNE?
- Will DS SSH be harvested by CESSDA -> EOSC in future? Are the semantics then retained?
- Comparison between before and after the vocabularies were connected. Are people increasingly using these vocabularies? Is searching easier?
- Connecting OntoPortal vocabularies to DANS Data Stations?
- Practice report, for the use case / question ‘How are the DANS Data Stations using external specific vocabularies? Practice report, with pros/cons, lessons learnt, things to be aware of technically and beyond.
- Documentation SKOSMOS – Dataverse available here: https://zenodo.org/records/8133723
- OntoPortal – Dataverse connection
Expected/Measured Impacts
- Use / increase in use of SKOSMOS – Dataverse connector
- Compare use before FAIR-IMPACT project, with after Slava started in FAIR-IMPACT (after initial presentations, after more presentations, after document published, etc.). Is there an increased use?
- use of the information by others, e.g. already use in OntoPortal-DV connection: https://github.com/IQSS/dataverse/pull/10145
- Increased use of metadata elements with controlled vocabularies by DANS Data Station depositors.
- e.g. use before the metadata with controlled vocabs like ELSST and CESSDA were present and after one year; and/or compare now with one year from now (pre-guide and post-guide / or pre and post increased guidance in general).
- Connection possibility of OntoPortal instances with Dataverse instances. Ideally also take up and use of this, e.g. connection of an OntoPortal instance with the new DANS Data Stations.